
그동안은 데이터베이스처럼 쓰는 구글 스프레드시트의 업데이트나 행번호 찾기를 위해 =ROW() 를 일일이 넣어줬다.
더 관리하기 편할 수도 있는데, 자동화된 스크립트로 반영해 줘야하는 것이 큰 이슈였다.
MATCH 함수를 이용해 찾고자 하는 행의 번호를 출력하도록 사용했는데, 추후 활용이 될지는 모르겠다.
=IF(IFERROR(MATCH(B2,'시트'!A1:A,0)),MATCH(B2,'시트'!A1:A,0),0)
'시트'라는 시트에 A열에 찾고자 하는 키워드(고유값)가 B2에 있다면, 행번호를 반환하는 수식이다.
이수식은 QUERY를 사용하여 질의하는 환경에서 사용가능하고, 기존 데이터를 출력하는 부분에서는 =ROW() 수식으로 유지하는 것이 더 낫다.
특정 행을 찾아서 지우거나 업데이트, 추가된 값을 넣고자 할 때, 질의되는 키워드를 B2에 넣어 행번호를 찾는 수식이 적용된 셀의 내용을 반환받아 처리할 수 있다. 게시판처럼 활용되거나 고유값을 사용하는(해시로 만들어 넘버링하거나 절대번호가 있는) 환경에서 행 위치에 적용 가능하다.
구글 스프레드시트에서 조건을 찾은 뒤, 특정 컬럼값만 출력하는 것은 이중 query로 처리했다. 조건에 의해 모든 행 레코드를 반환하는데, 컬럼의 이름을 출력하도록 한뒤 transpos 하면 조건이 1컬럼에 위치한 구조가 된다. 1컬럼에 해당하는 where 문을 query로 만들면 해당 행을 찾게되고, 최상위 행에는 최초 query의 조건이 위치되어 다시 transpos 하게 되면 원하는 컬럼만 추출되는 형태이다.
기존 관계형 데이터 베이스에서는 query 를 사용하 각 배열에서 원하는 값만 배열 이름이나 순서로 일일이 출력했는데, GS에서는 이중 쿼리로 일괄 출력이 가능하다. 만일 기존 언어로 처리한다면, 다시 db에 넣고 조건문으로 찾은뒤, 첫번째 조건을 재출력하여 순차적으로 보여주는 방법이 있다.
그런데 그런 방법은 GS에서 LIKE로 찾은 조건에 해당하는 1행이나 별도 변수에 넣고 사용해야하는 복잡함이 있어 동일하게 활용하기는 번거롭다. 정리하면서 GS 만의 특징으로 가능한 출력법에 대해 인지했다.
출력되는 내용이 비교해야하는 상황이라면 복잡한 배열 파싱의 연산을 위한 코드를 작성하지 않고, 간단하게 비교 구문을 추가해 줄 수 있다.
GS 가 해야할 일, 파이선이 해야 할일을 잘 분배하려면 많은 시행착오를 통해 각각의 장점을 파악하는 것이 필요하다.
[1차조건 - 항목](데이터는 지웠다.)
[TRANSPOS]
[2차 조건 - 2월]
[TRANSPOS]
2월 조건에 12월도 걸려 버렸지만, 이를 잘 예외처리하면 16년 2월과 17년 2월의 비교를 아주 간단히 처리할 수 있다.
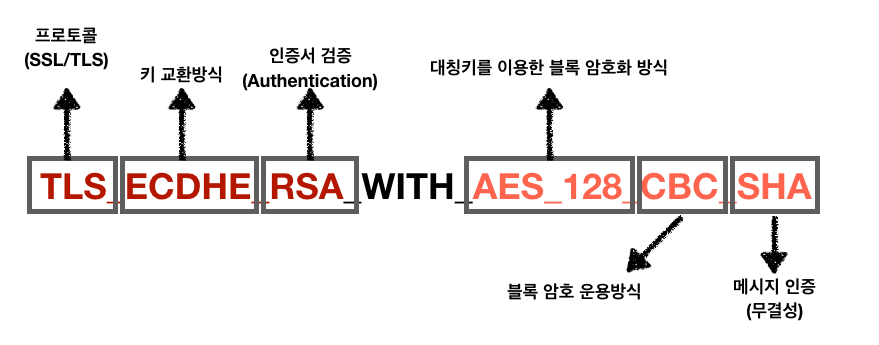


















댓글 달기